
Comparaison de périodes
Trucs et Astuces
✓ d.side Replay
Pourquoi comparer deux périodes ?
On peut être amené à comparer deux périodes dans différentes situations.
Voici quelques cas d’usage :
- Suivi des performances :
- Evolution de la charge ou du comportement d’une base Oracle.
- Un traitement a pris plus de temps que d’habitude : pourquoi ?
- Un traitement a tourné plus vite que d’habitude : comment comprendre et pérenniser ce meilleur comportement ?
- Une consommation anormale de ressources est détectée : que s’est-il passé ?
- Comment se comportera une base après une migration OS ?
- On va migrer sur Linux : quelle incidence sur les performances ou la consommation ?
- Anticiper avant la mise en production d’une évolution applicative : ERP, développement interne…
- Observer le comportement qu’aura un environnement après un upgrade de version Oracle : en 19c, 20c…
- Projet de changement d’infrastructure :
- Migration vers ODA ou vers Exadata.
- Ajout ou suppression de CPU, changement sur la baie de disques, etc.
- Prévoir comment fonctionnera une application sur une architecture différente, pour la dimensionner.
- Etc.
Pour répondre à toutes ces demandes, d.side Replay offre une fonctionnalité de comparaison de périodes très facile à utiliser.
Comment comparer deux périodes avec d.side Replay ?
Pour exploiter cette fonctionnalité il est seulement nécessaire de collecter les deux activités que l’on souhaite comparer.
Quelques exemples :
- Une trace d’un traitement qui fonctionne bien et une trace du même traitement plus lent.
- Une collecte quand l’environnement est encore sous Windows et une collecte de la même activité sous Linux.
- Une capture de l’activité de production actuelle et une capture avec la charge que provoquera la prochaine version applicative.
- Etc.
On peut donc bien entendu comparer des activités qui ont été exécutées et collectées sur des environnements différents :
pas le même OS, pas la même version Oracle, une production avec un environnement d’intégration ou de tests de charge, une préproduction, etc.
Sélectionner la période 1
Une fois que les deux activités sont capturées et disponibles sous Replay, il suffit de sélectionner la première période, celle qui servira de référence à la comparaison :
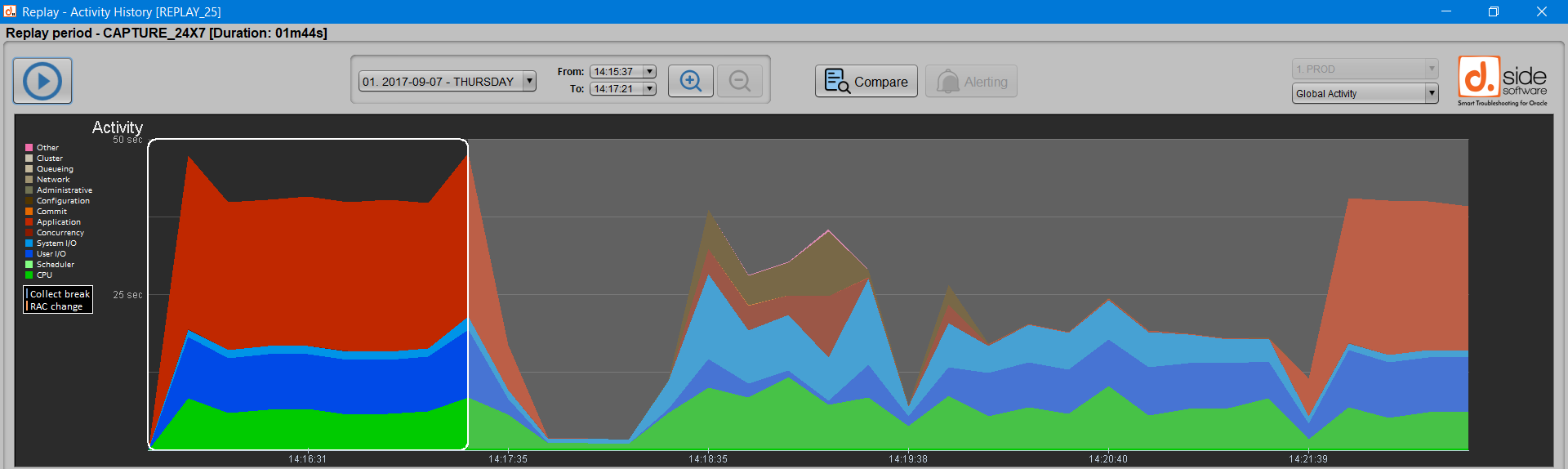
Cliquer sur le bouton “Compare periods” permet de valider cette première sélection :

Sélectionner la période 2
On peut ensuite choisir la seconde période, qui correspond :
- soit à l’activité que l’on souhaite comprendre a posteriori : traitement plus lent ou plus rapide, machine ou base plus chargée…
- soit à l’activité que l’on anticipe : nouvelle version applicative ou Oracle, nouvel OS…

Change owner
C’est dans cette fenêtre de sélection de la seconde période que l’on peut choisir un autre schéma de collecte afin de comparer des captures provenant de différents OS, de différentes version d’Oracle ou simplement de différents environnements. Pour cela il suffit de sélectionner le nouvel “Owner” dans la liste proposée :

Une fois la seconde période sélectionnée, en cliquant à nouveau sur le bouton de comparaison de périodes, on accède alors aux tableaux de résumé et de détails de la comparaison de ces deux périodes, afin de mettre en évidence les différences entre les deux activités sélectionnées.
Que nous apprend la comparaison de périodes ?
Le résultat de la comparaison de deux activités Oracle est décomposé en 5 onglets dans la fenêtre “Periods Comparison”.
Résumé et requêtes SQL
Le premier onglet “Summary” présente le comportement global des requêtes SQL et il permet ainsi d’évaluer en un coup d’oeil la stabilité de leurs performances et la stabilité de leurs plans d’exécution.
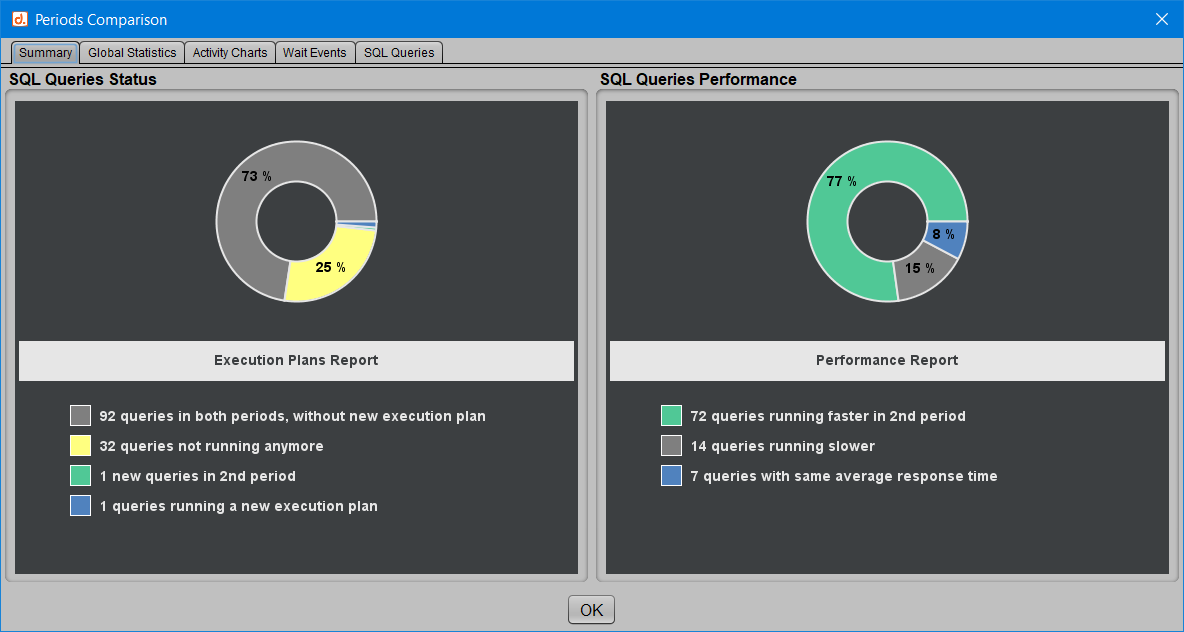
Sur cet exemple, on observe dans le graphique de gauche que :
[ ] Une requête n’apparaît que dans la seconde période.
[ ] Un quart des requêtes (25%) n’est plus exécuté dans la seconde période.
[ ] Une requête a changé de plan d’exécution.
[ ] Près des trois quarts des requêtes (73%) se retrouvent dans les deux activité sans avoir changé de plan d’exécution.
On apprend également à l’aide du graphique de droite “Performances” que près de 7 requêtes sur 10 tournent plus vite dans la deuxième période sélectionnée, alors que 16 requêtes, c’est à dire 17% de toutes les requêtes, sont plus lentes.
On a donc déjà une bonne idée de la tendance globale : la seconde période d’activité semble plus efficace d’un point de vue des performances SQL.
Activité globale
Le deuxième onglet “Global Statistics” nous présente à quoi correspondent les deux périodes sélectionnées : durée de chaque période, consommation totale et moyenne du temps passé dans Oracle ou en CPU, etc.
Davantage de détails sont encore affichés concernant certaines statistiques Oracle, dont le nombre de requêtes exécutées, le nombre de transactions validées, le nombre de blocs logiques ou physiques lus, etc.
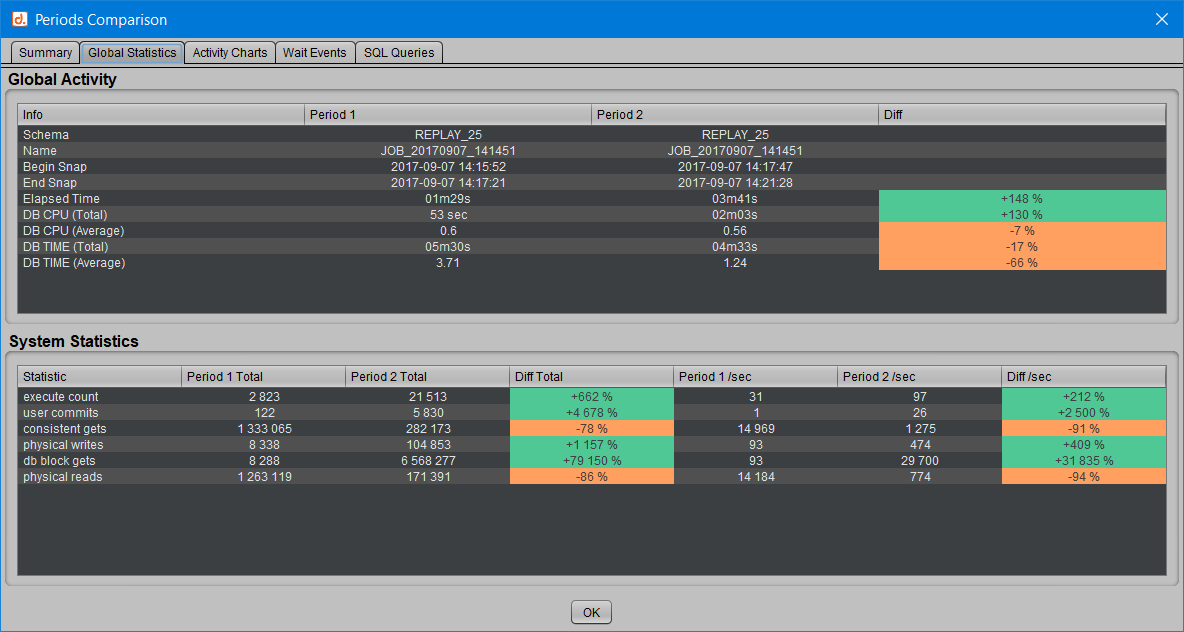
Pour chacune de ces statistiques systèmes, on voit le total cumulé pour chaque période, la moyenne par seconde et la différence entre les deux périodes.
On peut déjà vérifier dans cet onglet, au-delà du comportement des requêtes SQL, que l’on a été capable de réaliser plus de transactions, tout en consommant moins de ressources dans Oracle, dont la CPU et les lectures physiques.
Le code couleur est simple :
[ ] Une valeur affichée en vert signifie une augmentation entre la première et la deuxième période.
[ ] Alors qu’une valeur affichée en orange représente une diminution entre les deux périodes.
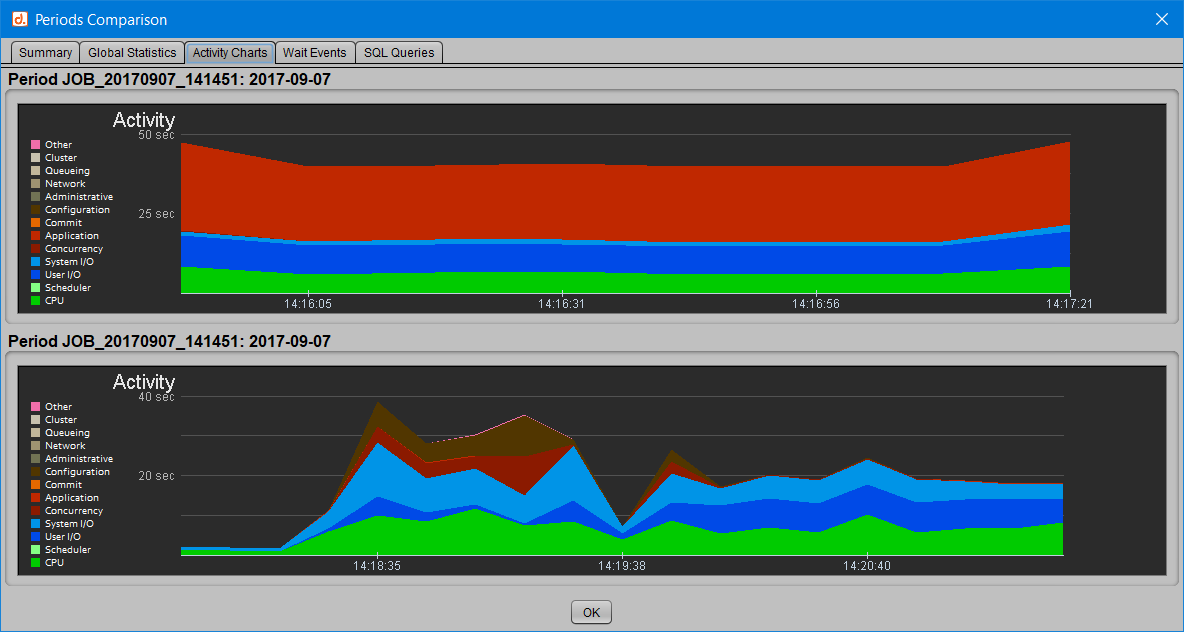
Courbes d’activité
Le 3ème onglet “Activity Charts” permet de superposer les profils d’activité de chacune des deux périodes sélectionnées.
On voit ainsi où est passé le temps dans Oracle : CPU et classes d’attentes.
Evénements d’attente
Le 4ème onglet “Wait Events” permet de comparer quel temps est consacré par Oracle à chaque attente ou chaque classe.
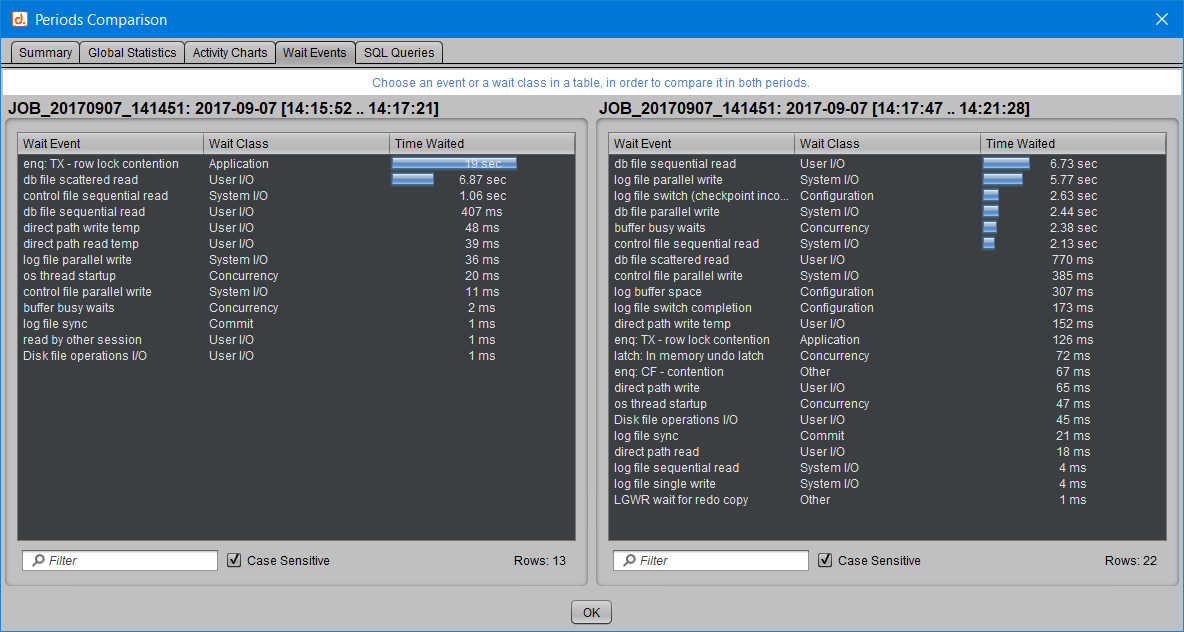
En cliquant sur un événement d’attente, celui-ci est mis en évidence en couleur bleue dans les deux périodes. On peut ainsi facilement constater que les attentes de type “enqueue TX” (dans l’exemple ci-dessous) ou “db file scattered read” sont bien moins présentes ou pénalisantes dans la deuxième période que dans la première.
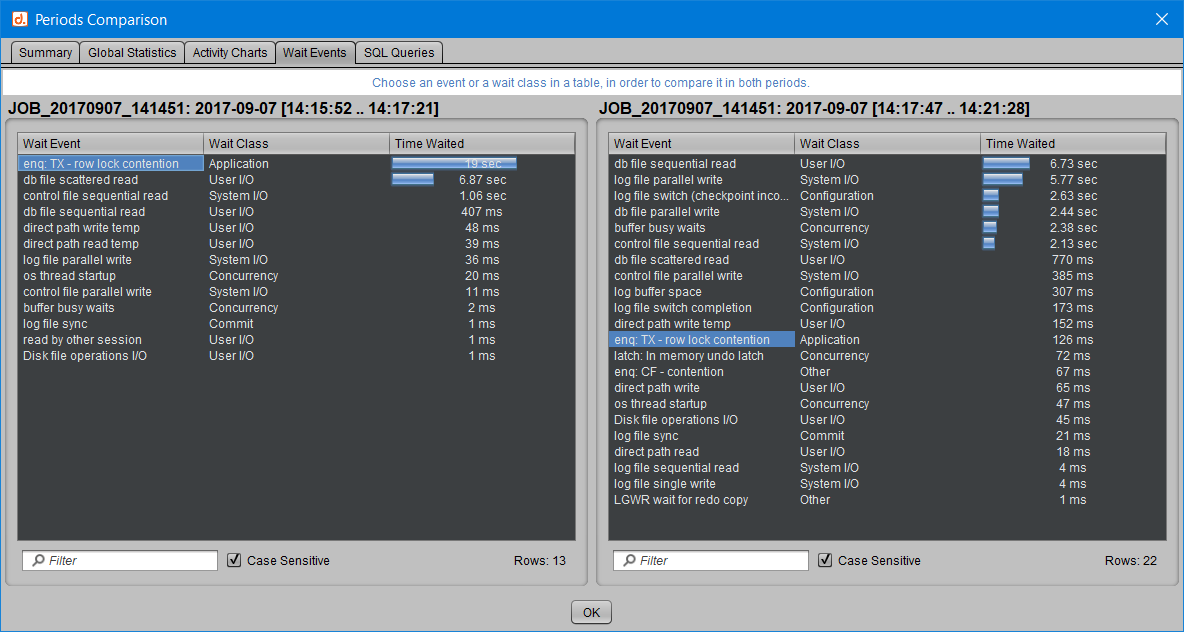
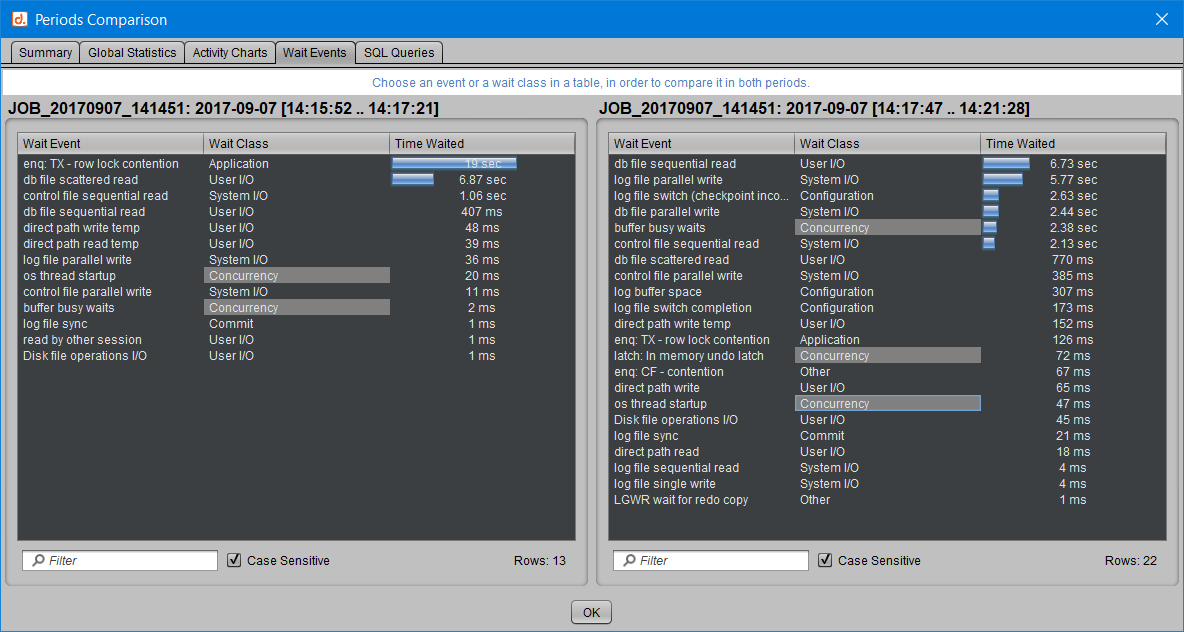
De même, on peut cliquer sur une classe d’attente, et ce sont alors tous les événements de cette classe qui sont mis en évidence par une couleur grise dans les deux périodes. Exemple en choisissant d’observer l’évolution des attentes de la classe “Concurrency” :
Détail des requêtes SQL
Le 5ème et dernier onglet “SQL Queries” apporte une vue détaillée du comportement de chacune des requêtes recensées dans l’une ou l’autre des périodes comparées.
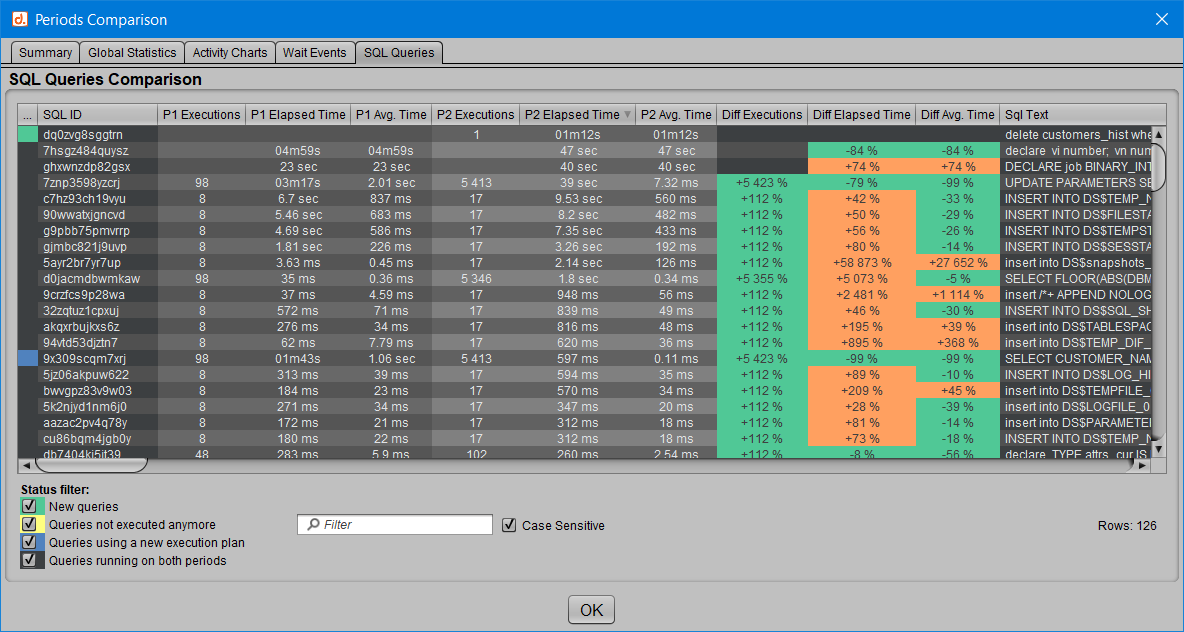
Chaque SQL_ID est présenté avec le nombre d’exécutions, le temps total d’exécution et le temps moyen d’exécution correspondants aux périodes 1 et 2, selon que la requête a été détectée dans ces périodes.
Ici, le code couleur des statistiques d’évolution est un peu différent :
[ ] On considère en vert ce qui va plus vite ou est exécuté plus souvent.
[ ] Et en orange ce qui correspond à un temps de réponse plus long ou un nombre d’exécutions en baisse.
Par ailleurs, si une requête n’est plus exécutée dans la deuxième période ou si elle n’apparaît que dans cette nouvelle activité, alors les colonnes “Diff” ne sont pas valorisées car il n’y a rien à comparer.
Ces requêtes possèdent d’ailleurs un “status” qui est associé à une couleur respectant le même code couleur que dans l’onglet “Résumé” présenté plus haut :
[ ] Requêtes apparues uniquement dans la seconde période.
[ ] Requêtes présentes uniquement dans la première période et qui ne sont plus exécutées dans la seconde.
[ ] Requêtes présentes dans les deux périodes, avec un nouveau plan d’exécution dans la seconde.
[ ] Requêtes présentes dans les deux périodes et n’ayant pas supporté de changement de plan d’exécution.
On peut bien sûr filtrer sur ce “status”, ou encore sur un SQL_ID ou le texte d’une requête, et même trier pour faire apparaître en premier les requêtes qui se sont le plus améliorées ou le plus dégradées sur la deuxième période, etc.
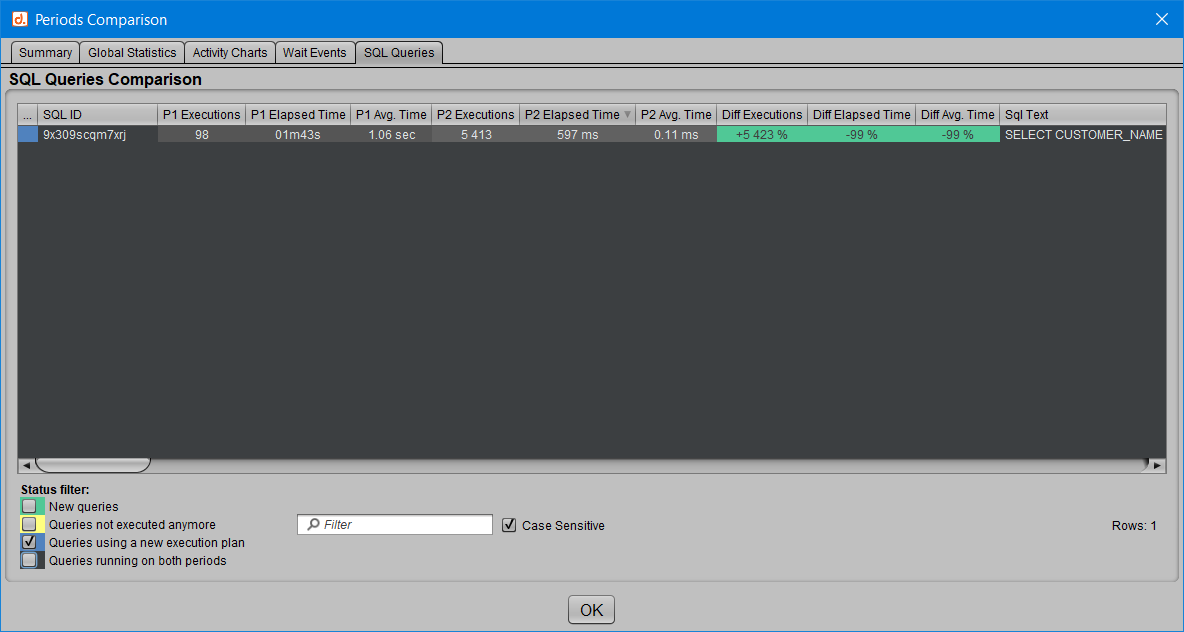
Dans l’exemple ci-dessus on n’affiche que les “[ ] Requêtes présentes dans les deux périodes, avec un nouveau plan d’exécution dans la seconde”, et on observe pour le seul SQL_ID concerné que le changement de plan supporté amène un gain important côté performances.
En double-cliquant sur une requête, on obtient encore davantage de détails sur son comportement dans les deux périodes, comme la tendance globale (plus rapide ou plus lente) et des statistiques d’exécution. Et si un nouveau plan d’exécution est détecté pour cette requête dans la seconde période, les deux plans d’exécution sont affichés en mettant en évidence ce qui les distingue.
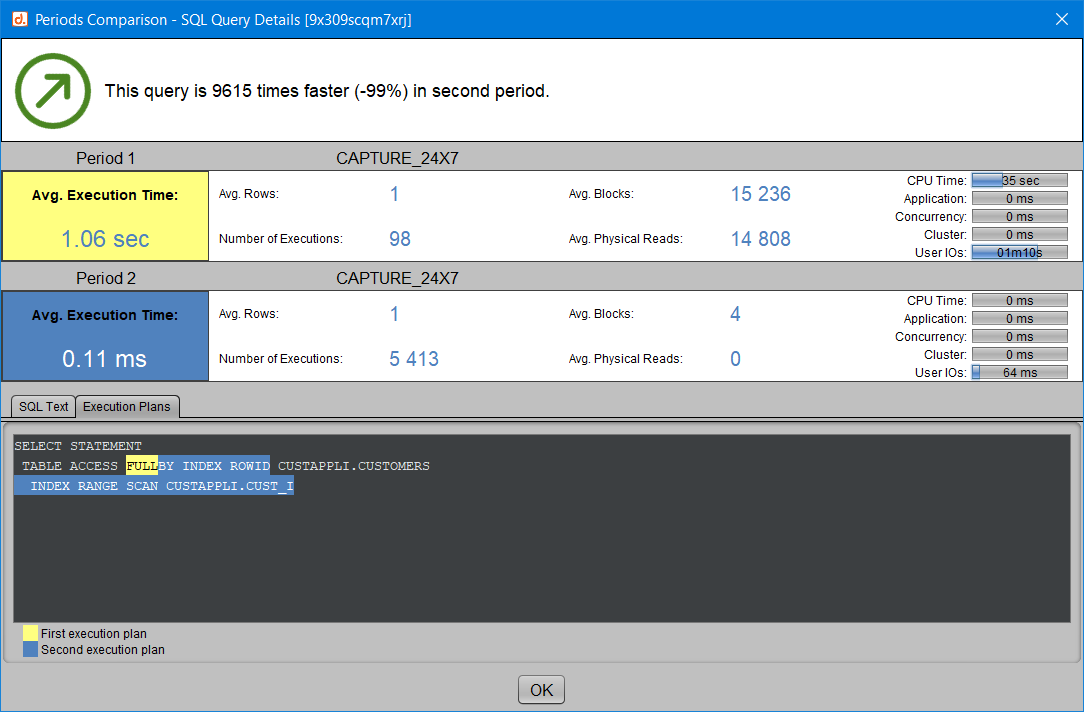
Pour plus d’informations concernant la comparaison de plans, vous pouvez également vous reporter à l’article “comparer deux plans d’exécution“.
Amélioration ou dégradation : un peu de marge
Dans certains cas, les variations de consommation ou de temps de réponse sont si faibles entre les deux activités qu’on ne souhaite pas considérer qu’il s’agit d’une amélioration ou d’une dégradation. Si l’on préfère admettre qu’une requête qui varie peu entre deux captures fait plutôt preuve de stabilité, alors l’utilisation d’une marge devient intéressante. Dès lors, deux statistiques qui se trouvent suffisamment proches pour rester dans cette marge sont considérées égales.
Prenons l’exemple d’une marge positionnée à 5% dans les préférences utilisateur :
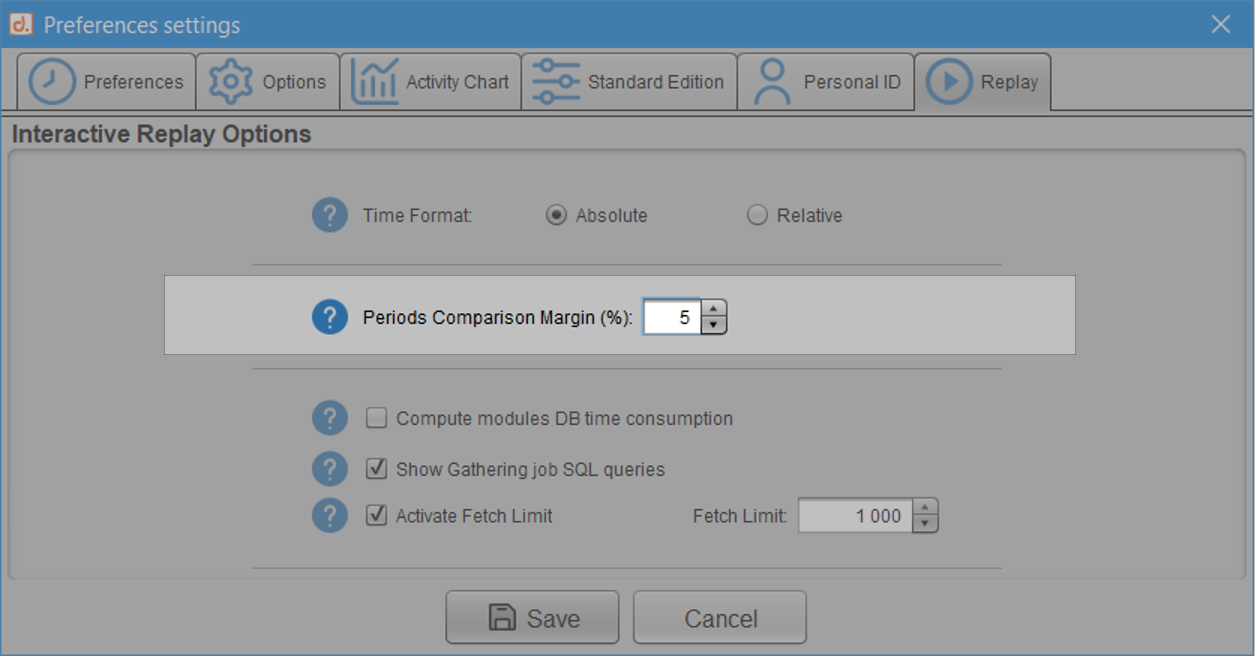
Dans ce cas, si l’écart de temps de réponse pour une requête SQL entre les deux périodes n’excède pas 5%, on considère que cette requête est stable, que son temps n’a ni baissé ni augmenté.
Voyons comment cela se traduit pour une requête qui dure en moyenne 60 secondes dans la première période et qui passe à 59 secondes dans la deuxième : sans la notion de marge présentée ici, on considère que cette requête est plus rapide, car elle a gagné 1 seconde. Avec une marge positionnée à 5%, on considère que le gain constaté (1 seconde gagnée sur 60 = une amélioration de moins de 2%) n’est pas suffisant pour placer cette requête dans la catégorie des requêtes devenues plus rapides dans la deuxième période. Il faudrait que la requête prenne 3 secondes de moins (5% de 60 secondes) pour être considérée plus rapide, ou qu’elle prenne 3 secondes de plus pour être considérée plus lente. Si en revanche, comme c’est le cas ici, elle dure entre 57 secondes et 63 secondes, alors on considère que son comportement n’a pas évolué.
Comme nous comparons des temps en millisecondes, il suffirait d’un écart de une milliseconde pour prononcer une augmentation ou une diminution de temps de réponse. L’utilisation de cette marge permet ainsi de lisser le résultat par rapport à une comparaison stricte.
Conclusion
Quel que soit votre objectif de comparaison, a posteriori pour comprendre, ou en étude pour anticiper, il est très simple d’observer les changements positifs ou négatifs entre deux activités Oracle, et d’obtenir des statistiques de résumé ou détaillées, dans un visuel très facile à partager entre les équipes.

