
Interpréter les informations de l’écran principal
Trucs et Astuces
✓ d.side temps réel
✓ d.side Replay
Comment se comporte une instance Oracle ?
Pour déterminer si l’instance Oracle surveillée se comporte bien ou si elle rencontre des problèmes, on peut chercher à vérifier sur l’écran principal la présence d’éléments en “excès”.
Voici une liste d’indicateurs qui, s’ils sont considérés comme excessifs, peuvent signaler un point ayant une incidence sur les performances de la base.
 Consommation de CPU
Consommation de CPU
Trois statistiques sont intéressantes ici :
DB CPU usage :
La consommation de CPU par l’instance Oracle.
Par exemple, Oracle est en train d’utiliser un peu plus d’une des 4 CPUs de la machine sur le dernier intervalle écoulé, ce qui représente 28% des ressources CPU disponibles :
![]()
Host CPU usage :
La consommation de CPU au niveau de la machine, du serveur de base de données.
Exemple :
![]()
Parse CPU :
Cliquer sur la statistique “Parse CPU” permet d’entrer dans le “Shared Pool Analyzer” qui met en évidence les éléments amenant une consommation importante de mémoire ou de CPU en shared pool pendant la phase de parsing des requêtes SQL. Cette phase correspond à l’analyse de la requête SQL et au calcul du plan d’exécution par l’optimiseur Oracle. Si elle consomme trop de CPU c’est ici que l’écran principal avise l’utilisateur.
Exemple :
![]()
 La courbe “Global Activity”
La courbe “Global Activity”
La courbe “Global Activity” permet de mesurer la consommation de CPU et les attentes.
Cette courbe peut être comparée à la valeur de la statistique “Average Active Sessions” dans le panneau de gauche “Main Statistics” car ces deux informations signifient la même chose :
Consommation Oracle = "DB Time" = "Active Sessions" = CPU + attentes
La courbe d’activité globale peut être associée à trois échelles différentes.
Voici quelques exemples, pour lesquels on considère que l’intervalle entre deux snapshots est de 5 secondes, ce qui est sa valeur par défaut :
“Summed”
le cumul de CPU et d’attentes sur les 5 dernières secondes passées.
Par exemple : 10 secondes de CPU et 15 secondes d’attentes signifient que 2 CPU sont utilisées en permanence et 3 sessions constamment en train d’attendre des ressources pendant les 5 dernières secondes écoulées.
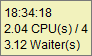
“Average”
un calcul “par seconde” est réalisé. On observe alors directement les 2 CPUs et les 3 sessions en attente. Cela est confirmé en survolant la courbe avec la souris :
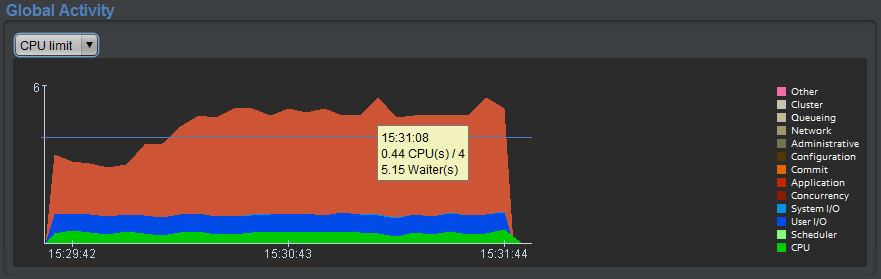
“CPU limit”
c’est la même interprétation, mais le nombre de CPUs est matérialisé par une ligne horizontale.
Exemple avec peu de CPU utilisée (surface en vert) par rapport aux 4 CPUs disponibles, et 5 sessions en permanence en attente sur un verrou (classe “Application”) :
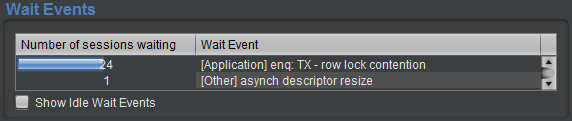
 Panneau “Wait Events”
Panneau “Wait Events”
Pour détailler les différentes classes d’attentes visibles dans la courbe, le panneau “Wait Events” précise le type des attentes et le nombre de sessions concernées.
Le nombre de sessions bloquées est ramené au nombre total de connexions, afin d’observer facilement si un événement d’attente a une incidence forte sur l’activité métier car il pénalise du monde.
Ici, 24 sessions sont bloquées par un verrou de type “enqueue TX”, et ces 24 sessions représentent quasiment la moitié des 49 connectés :
Le nombre de connexions établies est visible dans le panneau “Connection Info” en haut à gauche de l’écran principal :
![]()
 Requêtes SQL
Requêtes SQL
La plupart du temps c’est l’exécution des requêtes SQL qui génère la consommation de ressources : CPU comme attentes.
On cherchera si une requête par exemple consomme beaucoup de CPU, ce qui se traduit par une valeur de “CPU usage” élevée.

Dans l’extrait ci-dessus, la première requête consomme beaucoup de CPU, alors que la seconde provoque aussi des IOs (lectures physiques sur disques), pendant que la dernière requête UPDATE passe tout son temps (Elapsed Time = Application = 1 minute 46) à attendre qu’un verrou (classe d’attente “Application”) soit relâché.
Pourcentage d’attentes
- La barre de progression sous la valeur “IOs=3.01 sec” de la deuxième requête représente 100%. Cela signifie que ce SELECT totalise l’intégralité (100%) des temps d’IOs constatés sur la période, toutes requêtes confondues.
- La barre de progression sous la valeur “Application=1m46s” de la troisième requête représente également 100%, signifiant de la même manière que cet ordre SQL est responsable de la totalté des attentes sur verrou cumulées au cours du dernier intervalle.
- La barre de progression sous la valeur “Elapsed Time=01m46s” n’est pas tout à fait à 100%. En effet, les autre requêtes représentent 4 + 4.56 = près de 9 secondes. C’est assez peu, mais cela correspond à environ 7% du cumul des “Elapsed Time”. La barre de progression de l’ordre UPDATE affiche donc presque 93% puisque cet ordre SQL (qui a pris 1 minute 46) correspond à lui seul à 93% des trois ordres SQL visibles (qui cumulent 1 minute 46 + 4 secondes + 4.56 secondes = environ 1 minute 55).
Autre exemple, 100% en “CPU Usage” signifie que la requête passe tout son temps sur la CPU, et qu’elle consomme donc, sur les 5 dernières secondes écoulées, une CPU en permanence.

Si cette requête est exécutée deux fois en même temps (par deux sessions simultanément, par exemple), alors on aura un temps “Elapsed” de 10 secondes et toujours 100% de CPU, indiquant un excès de consommation de CPU, sans préciser qu’il s’agit de 2 CPUs. 100% indique qu’on consomme au moins une CPU en permanence, sans détailler le nombre précis, car l’objectif sur l’écran principal est de mettre en évidence les consommateurs excessifs de ressources. Double-cliquer sur cette requête permettra alors d’obtenir toutes les précisions nécessaires.
 Information “Last refresh”
Information “Last refresh”
Un dernier élément sur l’écran principal peut parfois mettre sur la piste d’un ralentissement global. Il s’agit de la date du dernier snapshot :
![]()
Quand l’information, comme ici, est affichée en couleur, cela signifie qu’il a fallu plus d’une seconde pour récupérer d’Oracle les éléments constituant le dernier snapshot, ce qui n’est pas habituel.
En survolant cette date on obtient le temps qui sépare les deux derniers snapshots :
![]()
Par défaut chaque intervalle entre deux snapshots est configuré pour 5 secondes. Ici on a un peu plus de 6 secondes, ce qui signifie que le dernier snapshot a mis plus d’une seconde pour être complété. La plupart du temps cela peut provenir du réseau ou de la quantité d’informations à traiter en shared pool quand cette zone mémoire d’Oracle est surdimensionnée, par exemple, ou mal exploitée (non utilisation de bind variables).
Ce “Last refresh” en couleur n’indique donc pas directement la cause mais est un symptôme d’une lenteur générale dans les requêtes envoyées à Oracle.
Conclusion
Si aucune statistique de consommation de CPU, de ressources (IOs…), ou d’attente n’est importante (on cherche un “excès”), alors il est très probable que l’instance Oracle surveillée ne rencontre pas de problème de performances.
Si en revanche l’instance Oracle souffre de lenteurs ou de blocages, alors on devrait observer sur l’écran principal des valeurs élevées de CPU, de ressources, de temps consommé ou d’attentes. Ces symptômes doivent facilement et rapidement mettre sur la voie de l’origine du problème : une requête SQL, une session bloquante, des contentions sur un composant particulier, etc… Davantage de détails qui permettront d’approfondir ce diagnostic peuvent être obtenus par exemple en cliquant ou double-cliquant sur les statistiques ou éléments concernés.
Pour établir un premier diagnostic permettant de définir si l’instance Oracle se comporte bien ou si elle rencontre des difficultés, suivre le cheminement proposé dans cet article semble donc constituer une bonne approche.

