
Group Matching
Trucs et Astuces
✓ d.side Replay
SANS BIND VARIABLES, LE DIAGNOSTIC SE COMPLIQUE
Lorsque de nombreuses requêtes unitairement rapides sont exécutées, il est difficile de déterminer parmi l’activité Oracle quels sont les ordres SQL les plus coûteux. Chaque requête peut ne correspondre qu’à quelques millisecondes de elapsed time, la rendant impossible à repérer dans des rapports d’activité, alors qu’au total l’ensemble de ces requêtes cumule plusieurs minutes ou heures de traitement.
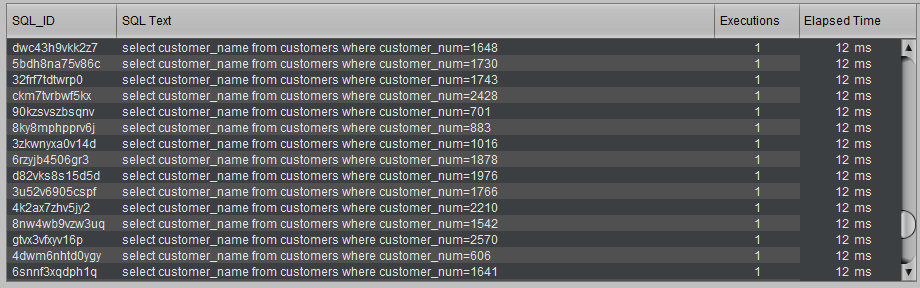
Prenons par exemple, les requêtes suivantes :
select name from customers where customer_num = 12; select name from customers where customer_num = 345; select name from customers where customer_num = 6789; ...
Ces requêtes, pourtant similaires, ne s’appuient pas sur une bind variable, et l’utilisation systématique d’une constante empêche d’avoir une vision globale du coût de ce type de requêtes.
Si chacune ne prend que 12 millisecondes, elles seront toutes “invisibles”, car on considère qu’aucune n’est consommatrice, même si 1 million de ces requêtes SQL similaires sont exécutées. Il est alors peu probable que l’on puisse expliquer facilement pourquoi Oracle a besoin d’autant de CPU pour fonctionner, ou pourquoi un traitement nécessite de tourner aussi longtemps, puisqu’on ne verra aucune requête particulière permettant de le confirmer.
Exemple :
OBJECTIF DE LA FONCTIONNALITE DE GROUP MATCHING
Grâce à la fonctionnalité de Group Matching, ces requêtes identiques peuvent désormais être regroupées afin de mieux observer leur coût total.
Cela signifie que dans le cas présent, au lieu de voir passer 1 millions de requêtes “sans importance” qui ne prennent que 12 ms chacune, d.side mettra en évidence un groupe de 1 million de requêtes similaires qui cumulent une consommation de 1 million x 12 ms, soit plus de 3 heures de traitement dans Oracle.
Ce regroupement de requêtes rend alors largement visible la cause de la consommation de ressources ou de temps dans Oracle.
Le diagnostic n’est plus le même.
COMMENT FONCTIONNE LE GROUP MATCHING
Quand le job de collecte Replay est lancé avec l’option Group Matching, alors il regroupe toutes ces requêtes similaires comme si elles s’appuyaient effectivement sur une bind variable :
select name from customers where customer_num = :1;
A présent on ne parle plus d’un million de petites requêtes différentes exécutées chacune une seule fois en 12 ms, et donc “invisibles” dans les rapports d’activité, mais d’un seul groupe de 1 million de requêtes. Cela permet de mettre en évidence très facilement le fait que ces requêtes, précédemment isolées, forment désormais un groupe qui totalise 1 million d’exécutions et plus de 3 heures de elapsed time, de CPU ou d’IOs.
Exemple :
Ce tableau résume la situation de la manière suivante :
Dans la première colonne, Replay nous indique que le groupe identifié par “8DACA5209C70E871” contient 1 048 230 requêtes qui ont été regroupées par le job de collecte car elles sont considérées similaires d’un point de vue de leur écriture. L’identifiant du groupe est calculé et attribué par la fonction de Group Matching, comme un SQL_ID est calculé par Oracle au moment du parsing de chaque requête.
Les requêtes de ce groupe, d’après la deuxième colonne, ont toutes un texte dont la forme ressemble à :
select name from customers where customer_num = 123
La valeur 123 affichée ici est seulement la première qui a été analysée et donc conservée à la création de ce groupe, par le traitement de collecte. Il y a eu en réalité plus de 1 million de valeurs différentes de customer_num passées à Oracle lors des exécutions, mais c’est la première observée qui est retenue par le Group Matching.
La colonne “Executions” indique que les requêtes de ce groupe totalisent un nombre d’exécutions identique au nombre de requêtes incluses dans le groupe : chacune a donc été exécutée une seule fois.
Enfin, et c’est l’objectif principal de cette fonctionnalité de Group Matching, le temps total cumulé par ces requêtes, plus de 3 heures, est à présent parfaitement visible. Contrairement à la situation initiale qui ne permettait pas de voir où est passé le temps dans Oracle, on observe désormais très facilement et très rapidement quels ordres SQL sont responsables de la consommation Oracle.
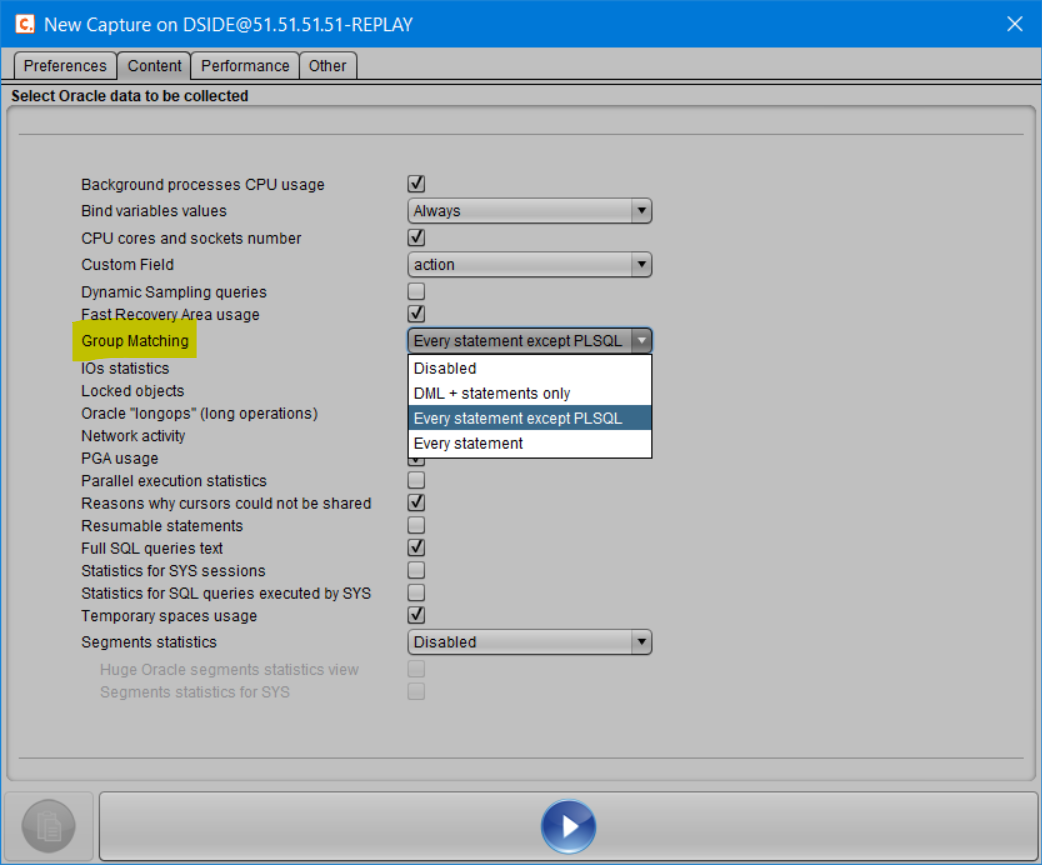
LES DIFFERENTS NIVEAUX DE GROUP MATCHING
La procédure GATHER du package DSIDE_REPLAY, qui permet de lancer le job de collecte, offre la possibilité de positionner l’option Group Matching selon 4 niveaux de granularité.
L’option Group Matching “Disabled“
C’est la valeur par défaut :
gmatch => 0
Dans ce cas, l’option n’est pas activée, la collecte traite et conserve tous les ordres SQL de manière indépendante, et Replay montrera un million de requêtes différentes ne consommant que 12 ms chacune.
L’option Group Matching “Every statement“
C’est la valeur “opposée” à la valeur par défaut :
gmatch => DSIDE_REPLAY.gmatch_all
Dans ce cas, le job de collecte vérifie pour tous les ordres SQL capturés s’ils appartiennent à un groupe de requêtes dont le texte est similaire.
L’option Group Matching “Every statement except PL/SQL“
Comme les blocs PL/SQL (blocs anonymes, procédures, fonctions, packages) exécutent eux-mêmes plusieurs requêtes SQL, il est souvent bien plus efficace de ne regrouper que les requêtes et pas ces blocs PL/SQL, afin d’éviter un “double travail” de la collecte.
Tous les blocs PL/SQL se verront alors affectés à un groupe unique dont l’identifiant sera ‘COMMAND:47’, même si ces blocs n’ont strictement rien à voir. Car le plus important est de rechercher et regrouper les requêtes sous-jacentes pour en estimer le coût cumulé, pas de chercher une ressemblance entre les blocs appelants.
Cela signifie que les deux blocs suivants, par exemple, même s’ils n’ont rien en commun à part d’être des blocs PL/SQL, se verront affectés au même groupe ‘COMMAND:47’, qui signifie “PL/SQL EXECUTE” :
begin dbms_stats.gather_table_stats(...); end; begin declare ... select count(*) from ...; end;
Quand une valeur de Group Matching est calculée par la collecte, le groupe est identifié par cette valeur (comme “8DACA5209C70E871” précédemment). Quand on décide avec cette option “Every statement except PL/SQL” de ne pas calculer de Group Matching pour les blocs PL/SQL, alors ceux-ci se voient affecter un identifiant commun “COMMAND:47”, ce qui permet d’économiser des ressources pendant la collecte en évitant un calcul peu utile sur le texte du bloc. Car les requêtes incluses dans ce bloc seront de toutes façons traitées par le Group Matching.
Ce niveau de Group Matching permet donc de consommer moins de ressources lors de la collecte, en plaçant tous les blocs PL/SQL dans le même groupe.
Pour le positionner, on valorise l’option de la manière suivante :
gmatch => DSIDE_REPLAY.gmatch_all_except_plsql
L’option Group Matching “DML + statements only“
On peut encore réduire davantage le travail du job de collecte, en ne calculant un Group Matching que sur les ordres SQL des types suivants :
SELECT INSERT, UPDATE, DELETE, MERGE CREATE TABLE, CREATE MATERIALIZED VIEW
Cela représente quasiment la totalité de l’activité Oracle : SELECT, DML et CREATE TABLE.
Tout ordre SQL d’une autre catégorie (ALTER INDEX, CREATE SYNONYM…) se verra alors associé un numéro de commande propre. Par exemple, tous les CREATE INDEX se verront affectés au groupe ‘COMMAND:9’.
La documentation Oracle « Reference » permet de voir à quel numéro de commande correspond quel type d’ordre SQL :
9 pour CREATE INDEX,
47 pour PL/SQL EXECUTE…
Avec ce niveau de Group Matching, tous les ordres SELECT, DML et CREATE TABLE seront toujours associés à un groupe de requêtes similaires pour favoriser la lecture de leur consommation. Et en même temps on regroupe tous les CREATE INDEX dans un groupe “COMMAND:9”, les blocs PL/SQL dans un groupe “COMMAND:47”, etc.
Dans cet exemple, les groupes par défaut qui n’ont pas été calculés sont surlignés en jaune :

Un premier groupe contient 7 blocs PL/SQL distincts. Puis 2 ordres CREATE INDEX différents se retrouvent dans un groupe unique. Et 11 opérations différentes de LOCK TABLE sont affectées au dernier groupe. Comme pour tous les groupes, seul le texte du premier bloc PL/SQL, du premier ordre CREATE INDEX ou de la première opération LOCK TABLE est retenu.
Quant à eux, les ordres SQL de type SELECT, DML et CREATE TABLE font bien l’objet d’un calcul précis de leur Group Matching. On ne met pas tous les SELECT dans un groupe unique ou tous les INSERT dans un autre groupe global.
Ce niveau de Group Matching permet ainsi de réduire la quantité de groupes à créer, en se concentrant sur les ordres SQL les plus importants.
Pour l’activer, on passe l’option suivante à la procédure DSIDE_REPLAY.GATHER :
gmatch => DSIDE_REPLAY.gmatch_only_dml_ddl
COMMENT ACTIVER LE GROUP MATCHING
Les différents niveaux de Group Matching présentés sont positionnés au lancement de la collecte par le package DSIDE_REPLAY.
Exemple :
execute DSIDE_REPLAY.GATHER (interval=>60, iostats=>true, gmatch=>DSIDE_REPLAY.gmatch_all, pga=>true);
Bien entendu, ces différents niveaux de Group Matching sont également disponibles depuis la d.side Console lorsque l’on démarre un nouveau job de collecte.
CONCLUSION
Cette fonctionnalité est très utile pour détecter quelle forme de requêtes consomme le plus de ressources dans Oracle quand les ordres SQL correspondant ne sont pas visibles du fait de l’utilisation de constantes au lieu de bind variables dans leur écriture.
Le Group Matching est souvent activé ponctuellement pour mieux appréhender et observer une vue globale de l’activité et mettre en évidence les requêtes SQL responsables de la consommation Oracle.
Différents niveaux de granularité permettent d’exploiter cette option Group Matching de manière à obtenir une vision plus ou moins détaillée de l’activité, tout en adaptant la consommation CPU nécessaire au calcul des groupes par la collecte.
Enfin, sauf exceptions, il est souvent plus efficace d’utiliser des bind variables que des constantes. Si le Group Matching permet de mettre ces écritures en évidence, faire en sorte que les requêtes soient ensuite réécrites avec des variables (via un développement ou à l’aide du paramètre Oracle cursor_sharing) est une piste d’amélioration des performances qui devrait être étudiée. Ce sujet est d’ailleurs abordé dans l’article https://www.dside-software.com/blog-shared-pool-analyzer/.

